 Annotations
AnnotationsImage Annotation

Image annotation is essential for training AI models, used in fields like medical imaging, content moderation, retail, agriculture, robotics, and security to enable object detection, classification, and automated decision-making.

Bounding box annotation involves drawing rectangular boxes around objects in images or videos to identify and classify them. It's a common technique in computer vision tasks like object detection and image recognition.

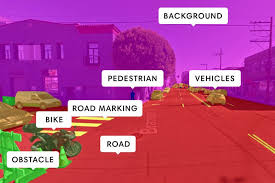
Semantic segmentation is a computer vision technique that involves classifying each pixel in an image into a specific category, allowing for detailed understanding of the image by identifying and labeling different objects or regions.

It’s used to draw accurate outlines around objects in polygon shapes for identifying and locating items in videos and images. This method is ideal for marking complex and irregular shapes in tasks like image segmentation or object detection.

Polyline annotation involves drawing connected line segments on images to outline paths, boundaries, or edges of objects. It's commonly used in tasks like road detection, lane marking, and object tracking in computer vision.

Polyline annotation involves drawing connected line segments on images to outline paths, boundaries, or edges of objects. It's commonly used in tasks like road detection, lane marking, and object tracking in computer vision.

Semantic labeling assigns descriptive tags to different regions or elements in data, such as images or text, to identify and categorize their meaning or function. This helps in understanding and analyzing the content more effectively.

3D point cloud annotation involves labeling points in a 3D space, often captured by sensors like LiDAR, to identify and classify objects or structures. This technique is commonly used in applications like autonomous driving, robotics, and 3D modeling.
Video Annotation

Video annotation involves labeling or tagging frames or segments within a video to describe its contents. This process is essential in various applications, particularly in machine learning, where annotated videos are used to train models for tasks like object detection, action recognition, and more.

Landmark annotation involves marking key points on objects or structures within images or videos. These key points, or "landmarks," are often used in computer vision tasks such as facial recognition, pose estimation, and object detection. For example, in facial landmark annotation, points might be placed on the eyes, nose, and mouth to help a model understand the structure of a face.
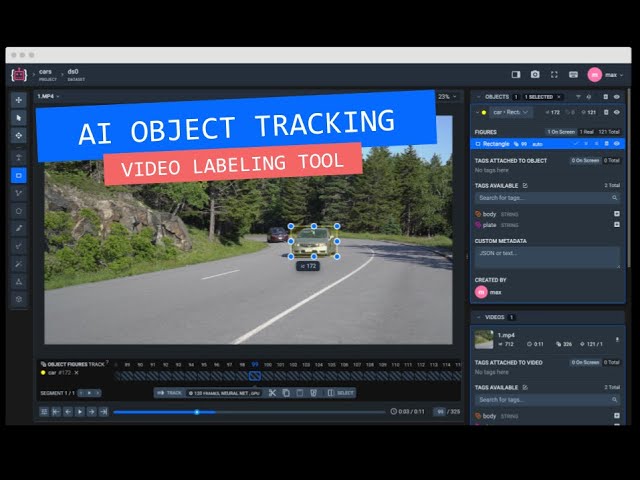
First, there’s object tracking, which entails keeping tabs on the whereabouts of designated moving targets inside a video. This annotation is crucial for uses like surveillance, driverless vehicles, and action recognition.

Event tracking monitors and records specific user interactions on websites or apps, like clicks and page views, to analyze behavior and optimize experiences.

Polygon annotation involves drawing polygons around objects in images or videos to precisely outline their shapes. This technique is used in computer vision to train models for tasks like object detection and segmentation.
Text Annotation

Text annotation involves adding labels, tags, or metadata to text data to provide additional information or context. This process is crucial for various applications in natural language processing (NLP), machine learning, and data analysis.

Text categorization, also known as text classification, is the process of assigning predefined categories or labels to text based on its content. This is a fundamental task in natural language processing (NLP) and is widely used in various applications such as spam detection, sentiment analysis, topic labeling, and content filtering.
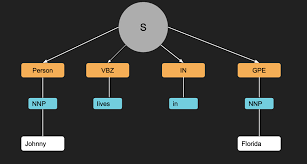
Part-of-Speech (POS) tagging is a process in natural language processing (NLP) that involves assigning each word in a sentence to its corresponding part of speech. This could be a noun, verb, adjective, adverb, preposition, conjunction, etc. POS tagging is an essential step in various NLP tasks, such as parsing, information extraction, and text-to-speech systems.
Whereas entity annotation is the location and annotation of certain entities within a text, entity linking is the process of connecting those entities to larger repositories of data about them.

Linguistic annotation is the process of adding explanatory notes or labels to text data, often to provide information about various linguistic features. This can include tagging parts of speech, identifying named entities, or marking syntactic structures. It's commonly used in linguistic research, natural language processing, and developing language models.
Audio Annotation

Audio annotation involves labeling and tagging audio data to provide context or metadata, making it easier to analyze, process, and utilize for various applications.
It is used in speech recognition, voice command systems, emotion detection, sound event detection, language learning, medical diagnostics, music analysis, and media organization.
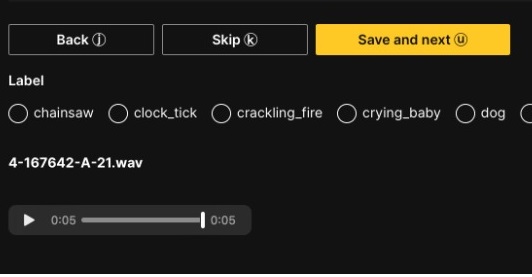
Speech-to-text transcription is the process of converting spoken language into written text. This can be done either manually by a human transcriber or automatically using speech recognition software.
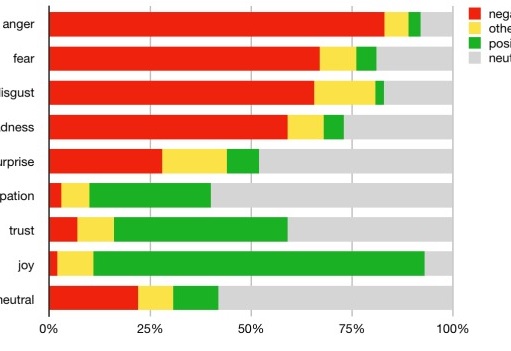
Audio classification is the process of categorizing audio signals into predefined classes or categories. This can involve identifying different types of sounds, music genres, spoken languages, emotions, or environmental noises within an audio file.

Labeling audio data with the expressed emotions is beneficial for sentiment analysis. Sound Event Detection involves identifying and labeling specific sounds or events within an audio clip, such as doorbells, alarms, or animal sounds.

Language identification, also known as language detection, is the process of determining the language in which a given piece of text or spoken content is written or spoken. This is useful in various applications, including text processing, speech recognition, multilingual systems, and content management.
Other Annotations


Geospatial annotation is used in adding labels and information to maps or geographic data to explain details about specific locations or features. This helps make geographic information clearer and easier to analyze.
Semantic annotation involves adding meaningful labels and metadata to text, images, or other data to provide context and understanding about their content. It is used to enhance search engines, content management, NLP, knowledge graphs, digital libraries, education, and healthcare.

LiDAR annotation involves labelling and tagging data collected from LiDAR (Light Detection and Ranging) sensors, which produce detailed 3D point clouds of environments. This process is crucial for interpreting the data and applying it in various applications.

Segmentation is used in image processing, computer vision, and machine learning to divide an image or 3D point cloud into distinct, meaningful regions or segments based on specific criteria, simplifying analysis, enhancing accuracy, and facilitating targeted tasks.